You may remember Jack Grieve’s swear maps of the USA. Now he has a nifty new web app called Word Mapper that lets anyone with an internet connection make use of the raw data behind those maps.
Being a mature grown-up, I put on my @stronglang hat and went searching for swears and euphemisms. What emerged were some intriguing – and visually very appealing – patterns of rude word use in contemporary discourse:


About 60 maps follow, so fair warning: It’s an image-heavy post.
Below are heat maps for: af (as fuck), asf (as fuck), badass, bullshit, cock, crappy, dammit, damnit, damned, dang, dick, dickhead, douchebag, effing, fart, freakin, freaking, frick, frickin, friggin, fuck, fucked, fucker, fuckers, fuckery, fuckin, fucking, fw (fuck with), goddamn, gtfo (get the fuck out), heck, idgaf (I don’t give a fuck), lmfao (laughing my fucking ass off), mf (motherfucker/-ing), mofo, motherfucking, nigga, omfg (oh my fucking god), piss, pissed, pissy, prick, scum, shit, shits, shitty, shittiest, shitting, slutty, stfu (shut the fuck up), sucks, swear, tf (the fuck), twat, turd, wtf (what the fuck), wth (what the hell).
If this is your first visit to Strong Language, welcome.
Multiple meanings aren’t controlled for, so the name Dick is mixed in with vulgar dick, innocuous sucks with slang sucks, emotional freaking with intensifier freaking, and so on. The same goes for abbreviations like af, asf, fw, and mf, which allow for other possibilities, but the sweary usages predominate in US tweets.
Before you ask about asshole, bastard, bitch, crap, cunt, damn, darn, douche, faggot, fuckboy, gosh, hell, motherfucker, pussy, slut, or whore, these all featured in my earlier swear-maps post, which also describes the mapping method Grieve and colleagues used. Fuck and shit are repeated here for comparison (shit vs. shitty is particularly interesting) and because the fuck map is pretty asf.
Cocksucker, curiously, doesn’t make the cut. Nor, less curiously, do arse, bugger, wanker and other taboo terms more characteristic of British English. But I’m sure I missed a few – let me know in a comment. You can click on maps for larger images.
















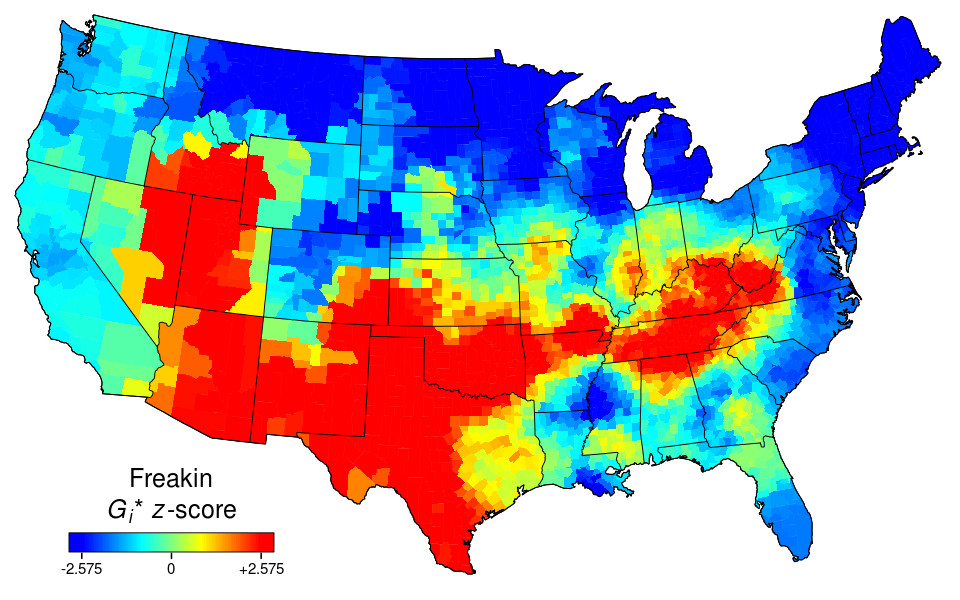







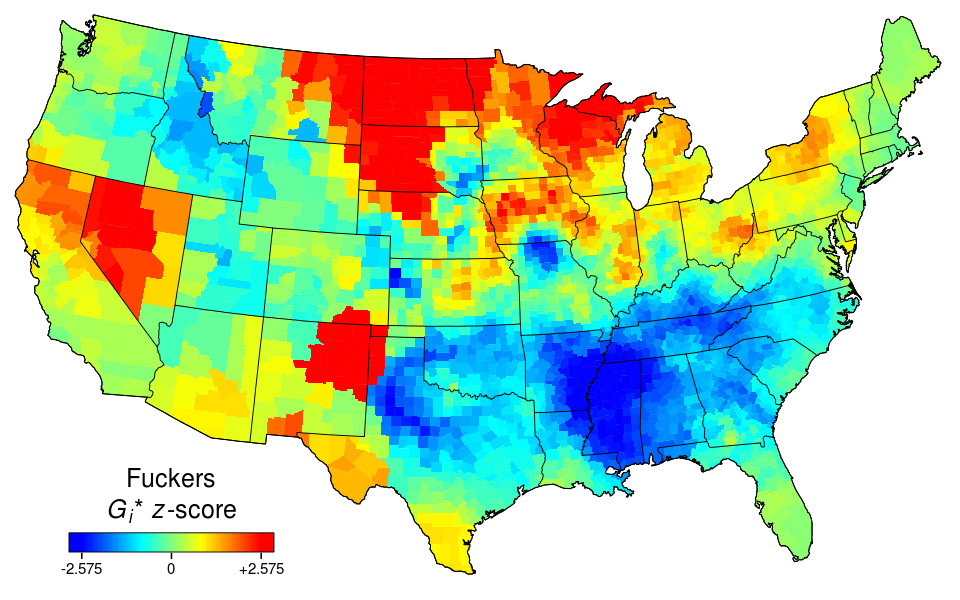































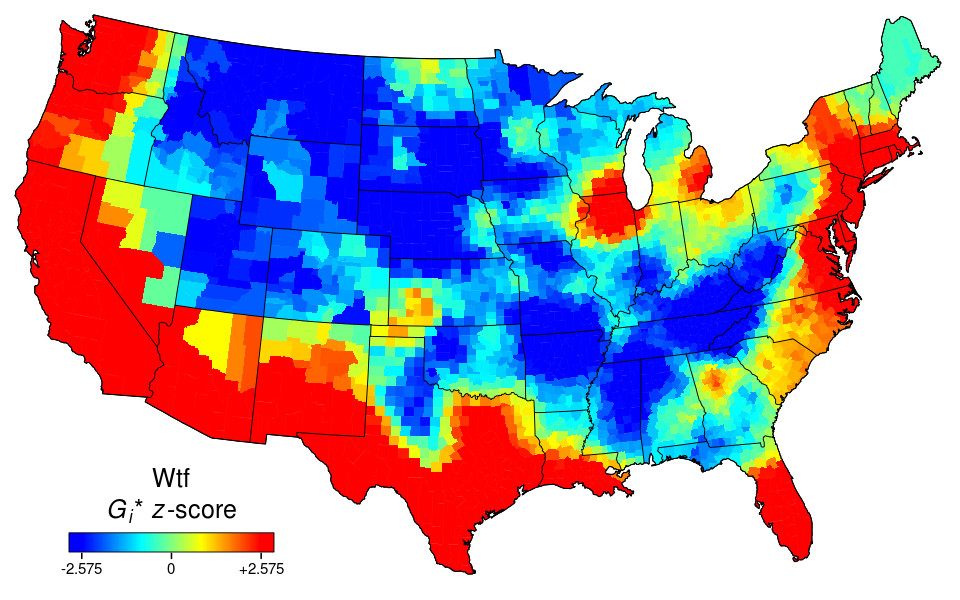

In a comment at Language Log, Grieve said the app should map any string of alphabetic characters in the top 10,000 words in the (8.9-billion-word) corpus. He confirmed to me that this will be extended in due course. Multi-word phrases don’t work yet, but will eventually. For hyphens, use full stops (periods).
Grieve hopes to set up Irish and British versions at some point (excuse me while I omfg) and to make other technical refinements. In the meantime, there’s endless fun to be had with the current US Word Mapper, and it’s impressively fast to use. You can even look up non-swearwords, but there’s a time and a place for that kind of carry-on.

What the fuck?
LikeLiked by 1 person
O K, so I live north of Boston and I definitely have a potty-mouth! lmfao!!!!!
LikeLike
Mormons say “freaking”. Who knew?
LikeLiked by 1 person
Tennessee and South Dakota appear to be the most tame
LikeLiked by 1 person
Nice research! Thanks for all these maps. I actually smiled at “heck” and “dang” because who actually uses those words lol? I live in NJ, the little space between New York City and Philadelphia. Swear words are one of our biggest exports!
LikeLiked by 1 person
I think I first saw heck in a football (i.e., soccer) comic as a child. It had occasional ironic currency among my brothers and me, but I don’t recall ever hearing it spoken in earnest.
LikeLiked by 1 person
Well, heck is something I said as a kid, but only because we weren’t allowed to say hell. It’s funny that people would use heck on Twitter. Why not just go for the real thing? That’s funny about you reading it but never hearing it spoken. I always heard heck spoken by adults who wanted to say hell but still wanted to be polite, and was allowed to do so myself. I had never heard dang spoken in real life until I moved to the southern states for a while.
LikeLike
The dang map is really striking. I’m sure some people cut loose on Twitter and elsewhere online in ways they wouldn’t in speech, but for many others their style of discourse and choice of vocabulary remain much the same in the different domains. After all, someone could be watching. 🙂
LikeLike
In the UK, nobody would consider “heck”, “dang”, “cock” or “dick” as being in and of themselves swearwords. “Cock” and “dick” used to refer to male genitalia might be regarded as rude, but only because of the reference.
The words are in common use in other contexts (we very rarely need to use the word “rooster”) and in compound words (such as “stop-cock”, which is nothing at all like a “cock-blocker”).
“Scum” and “turd” are certainly not even considered rude, and saying that something “sucks” to mean it is “crappy” is not rude (although when I was a kid, “crap” was mildly rude).
I wonder if the word “heck” (American bowdlerisation for “hell”) is a cognate of the Dutch word “fool”, maybe related to “hick”. There is a Dutch expression “wat de gek er voor geven wil”, that I think means something like “what a fool will give for it”.
LikeLiked by 1 person
What’s categorised as a swear word varies from person to person. We use it as a shorthand term here, but we also look at insults, vulgar words, sexual terms, and taboo vocabulary in general.
Re dang and heck: I refer to euphemisms in paragraph 2. Re cock and dick: I refer to words’ other meanings in paragraph 6. In case you skipping the writing.
Some of the words featured are mild, and may have drifted connotatively from their origins, but that’s no reason to omit them. You might not consider scum and turd rude, but they’re not exactly Sunday-dinner words. Dictionaries mark turd as vulgar, and scum is slang for semen (as in scumbag ‘condom’). Try calling someone ‘scum’ or ‘turd’ and see if they agree with you that the words are not rude.
LikeLiked by 1 person
There are some words that I would not use in polite company. Talking to my mother or aunt, I would not say “some twat let his dog shit on the footpath right in front of my house”, but I would say “some scumbag let his dog leave a turd on the footpath right in front of my house”.
LikeLike
I couldn’t help wondering if all of the ‘shitty’ and ‘crappy’ going on in the north was related to the weather! Would love to see some way of getting more context filters to explore ideas like that 🙂
LikeLike
Aye, it would be fun to be able to zoom in on the context a bit. Out of curiosity, I searched for collocates of shitty in the GloWbE corpus, filtered for the US, and got the following:
job 102
thing 98
little 88
things 80
day 71
jobs 47
situation 39
times 36
place 34
movie 31
movies 30
deal 30
behavior 27
music 26
stuff 23
ass 21
weather 21
and so on.
So weather is there, but it’s not among the strongest collocations. Results for crappy are broadly similar. I thought some of the ‘shitty day’ examples might be weather-related, but they nearly all have to do with lousy luck or circumstances, and a few are ‘shitty day jobs’.
LikeLike
@craftyrogue: You may be right. I remember seeing versions of this map when I traveled in Alaska.
LikeLiked by 1 person
Moving to New England, I noticed that up here, the word “weather” frequently gets used with an implicit negative adjective, as in “Looks like we’re headed for some weather.” or “We’ve got weather coming this weekend.” It’s like the phrase “shitty weather” is seen as redundant. That phrasing never seems to be used for unpleasantly hot or humid weather, just brutal cold, storms, or heavy snow.
LikeLike
Thanks for this, I missed the first sweary map post, though have now caught up with it. A couple of comments.
1. It is quite hard to pin down the methodology – even after plowing through a fair bit of the arcGIS desktop and such, I am still puzzled about some aspects (for instance I suspect ‘features’ refers to geographical features in arcGIS usage – no easy intro’ for non-geographers/social researchers: and I guess it is a manual for those who already know how to use it, since some of the example programs seem to make enormous assumptions about data handling); and one is not helped by e.g. what seems to be the basic paper on this – Understanding U.S. regional linguistic variation with Twitter data analysis, Yuan Huanga, Guo, Kasakoffa & Grieve, dec2015 – only legible if you stump up c.$42). Still, to avoid controversy, I will take the competence and honesty of the authors as read. And if anyone has a link to better background, then thanks in advance.
2. The Twitter analysis seems to have started as a way to find new words coming into the language: combined with the authors’ existing interest in geographical variation, geo-located tweets are a sensible source, web-pages for instance being somewhat less classifiable. The presentation on this by Grieve (London2 pdf – though I could only read it with Irfanview, as it would not open to any normal pdf reader) was quite interesting. However to extend the scope to defining general population usage seems to me to be going too far. I have seen an estimate that Twitter users are 2% of the US population (source not cited as have no idea of its validity, better estimates anyone ?), and I suspect that they are by no means representative of the general adult population in any country, with lots of class and other biases. This is compounded by mistrust.stemming from examples like the Microsoft tweet-bot experience.
(Contrast for instance the other corpora you make use of.)
Frankly the most interesting thing I have noticed about Twitter is the Trump lit-crit tweet:
http://languagelog.ldc.upenn.edu/nll/?p=24720#comment-1511067
LikeLike
Hi Gobbo
Thanks reading through our stuff! And sorry we’ve left you puzzled, although I do appreciate you giving us the benefit of the doubt in terms of our honesty and competence!
Anyway, we’ve got one of the biggest corpora of geo-coded data ever complied, so we’re using it for investigating all sorts of new research questions about linguistic variation on Twitter. We’re also doing our best to make the data accessible to other researchers. How well the patterns we and other researchers find generalize to American English is unknown (certainly not perfectly), since no one has a similar corpus of any other variety of language for comparison, but I suspect these swear maps, for instance, would be pretty similar across varieties (or at least those varieties where people swear).
In terms of methods, these maps plot the z-scores generated by a Getis-Ord Gi* local spatial autocorrelation analysis of normalized relative frequencies using a 30 nearest neighbors spatial weights matrix in R (Not ArcGIS like Yuan’s paper). Other spatial weights matrices can be used, as can other smoothing methods (like in Yuan’s paper), but the basic results are pretty stable, since the underlying patterns are pretty strong.
Best,
Jack
LikeLike
@ Jack Grieve
Dear Dr Grieve
Thank you for coming back so quickly with some helpful clarification: I apologize for this delayed acknowledgement, but I have been away.
What would help, I think, in getting to grips with what you are doing is some basic background, to establish to what extent the corpus you have is in any sense representative of wider language use (the statistical interrogation is a separate matter).
What one might look for is published or – perhaps available to you – unpublished data on all Twitter users, preferably in the continental USA. For instance Twitter, claiming “more than” 140 million US users in 2012, said they sent 340 million tweets a day (https://blog.twitter.com/2012/twitter-turns-six). This gives an average of 2.4 tweets/ day compared to the average for your corpus of 0.33 [London2.pdf corpus: 140 / (365+65 for extra oct-nov)] – though certainly these are different time periods, and they may not refer to the same USA definition.
2012 figures also suggested that Twitter users might form 50-60% of the US population However the Semiocast estimate was actually of 141.8 million accounts in the US on 1July 2012: Twitter’s own website now offers 320 million monthly active users and 79% of accounts outside the US: which might imply 67 million active users in the US – but I doubt that accounts and monthly active users correspond closely. In any case, all this suggests that Twitter users are some large proportion of the US population. But it is not clear to what extent any of this refers to private individuals.
[http://semiocast.com/publications/2012_07_30_Twitter_reaches_half_a_billion_accounts_140m_in_the_US]
However one would then ask why 40-50% do not use Twitter, and how else they might differ; and one would also note that your 7 million tweeters [London2.pdf] is a long way from the 140 million – plus and 67 million figures, and ask why these geo-locatable users might be different.
Have you been able to draw any comparisons between, for example, your average of 9 words a Tweet, and its distribution, and those of all tweets – e.g. by repetitive sampling from all tweets ? As the author of a study of techniques of authorship attribution, I suggest you are better qualified than me to suggest what characteristics of tweets might prove useful in this respect, though word usage analysis over time for those outside your corpus might prove interesting.
Overall I think I would need a little more hard data, to place much reliance on the general distributional effects you have noted. However, if this can be done, I shall be interested to see developments in your studies.
Thanks again for your explanations.
LikeLike
The common use of cock in Amish country amuses me, though I suspect they may be referring to the barnyard fowl.
I went to go wordmap “dilligaf” but the site is down. Hope you cunning linguists haven’t overloaded their server!
LikeLike
That’s exactly what has happened, unfortunately. But it should renew again soon, and a more stable version is in the works.
I think I looked up dilligaf when writing the post, because I went through these abbreviations (among others) and it didn’t feature on the Word Mapper. But it’s worth trying when the app returns.
LikeLike
Interesting how sharp the line between the Lowland South and the Inland South sometimes is… and that the Lowland South occasionally reaches all the way to Connecticut. 🙂
LikeLike
How is dang or freaking a bad word?
LikeLike
No one said they were ‘bad words’. Dang is a euphemism for damn, which was once a strong swear and is now a mild one. Freaking is a euphemism for fucking.
LikeLike
Oh, really? Sucks, swear, dang, and freak? The last two may be euphemisms. Swear has two meanings (to cuss and to promise). Suck just means to breathe from your mouth.
LikeLike
Dang and freaking I’ve already addressed. Swear has more than two meanings, but it’s appropriate to include it in a gallery of sweary maps. (Plus, I covered polysemy in the post.) Suck, if you can be bothered to look it up, means a lot more than ‘breathe from your mouth’, and many of its common meanings are vulgar.
LikeLike
Hi Gobbo,
This corpus represents mobile twitter from the US in 2014. It’s not the most interesting or important variety of English–I don’t think anyone doing working with geocoded Tweets thinks that–but it’s a real variety of language and most important the only variety of language that can be examined at this level of detail right now. But please don’t despair! More and more hard data is becoming available to dialectologists every day!
All the best,
Jack
LikeLike
@Jack Grieve
Thanks for this. Unfortunately it seems to me that the situation now gets more confused.
1. “It’s not the most interesting or important variety of English”: no, I don’t think that has been claimed. But if it is not very interesting, then why are you doing it ? And as for important, you include, in the London2.pdf, a slide showing the distribution across mainland USA of “percent African American (2010)”: now I do not know the spoken text which accompanied this slide, but the implication is that some of the geographical distributions of words are broadly comparable to this ethnic analysis. This tends towards a suggestion that Black Americans are responsible for a significant proportion of new words or usages (i.e. abbreviations such as “gmfu”). If this is what you are saying then it would seem to most people, I suspect an important suggestion. It should perhaps be taken together with the fact that 2/10ths of the top 10 emerging words involve ‘fuck’ and a similar proportion refer to drugs of some sort: you seem to lay yourself open to the charge of making some kind of sociological statement. I am not clear that your data should allow you to do this.
2. I am glad that “more and more hard data is becoming available”: but that raises two questions: why do you not work on such data, or alternatively, why do you express no interest in looking at the ways I have suggested above (and in my e-mail to you) to look for some kind of external validation of the data in your corpus ?
At the moment I can only repeat the adage that I offered you in my e-mail: the plural of anecdote is not data.
By the way I must apologize for suggesting in my first post that the figure of 2% was for Twitter users as % of the US population, this should of course have read that the geo-coded data was from 2% of Twitter users (although the point I was trying to make, that we had no idea how representative the 2% are remains valid), and the source which I forgot was of course London2.pdf. My regrets for this carelessness.
LikeLike
For information, I should add that I advised Dr Grieve of my last post and he has e-mailed me to refuse to continue this conversation. I find that disappointing and a little disturbing.
LikeLike
Which corpus did you use for your hot maps?
Thanks
LikeLike
Grieve used a large corpus of geo-coded tweets from 2013–14. My earlier sweary-maps post has additional details.
LikeLike
LOL
LikeLike
I’d love to see these maps include Alaska and Hawaii. Those states have a lot of transplants from other states and countries, and might have some interesting patterns.
LikeLike
Yes, hopefully one day we’ll have that data too.
LikeLike
Is there any way to control for the race of the Tweeter?
LikeLike
Not with the present app.
LikeLike
I was both amused and struck curious by my state in both sets of maps (first article and this one)
Oklahoma is a pretty mild state as far as swearing goes… and then theres me that swears like I live on one of the coasts LOL
I noticed something though – with trending abbreviations. Why are those apparently forming out of the south? Thats such an odd pattern to see. I’d have expected the heaviest usage of those to be around California primarily being the trendsetters they are. Maybe somewhat around New York. Just not the south. Weird.
LikeLike
My guess is that they’re popular in Black English. Compare the swear-abbreviation maps above with the non-sweary AAVE maps in this post at Language Jones.
LikeLike
can you map “hella” (also, “helluv” or hell of”)? i heard that only us san francisco bay area peeps use “hella”, period. i’m very curious to know if that is true.
LikeLike
This is completely untrue, I live in Florida and everyone I know (though notably more people from South Florida) use it. It was probably created and popularized in the San Francisco bay area, though.
LikeLike
What’s up with North Florida minus Jacksonville being a totally different color than the rest of Florida?
LikeLike
LikeLike
The actual (i.e. current rather than historic) taboo words seem to have been left out of the picture – was that a conscious decision, or is it simply that people aren’t using them?
Broadly, they’re words that carry the connotation of a sincere intent to abuse or oppress, rather than to shock or offend.
LikeLike
It’s not clear what words you mean – maybe slurs? Some do feature, either here or in the earlier set of sweary maps, but some don’t; it wasn’t intended to be comprehensive.
LikeLike
You’re right – slurs is exactly the word I should have thought of. Slurs seem to me to be the only category of words now truly treated as taboo, in the sense that they are the ones that you and I and most others here will actually make an effort to avoid saying, or discussing in a specific and frank way. The others (fuck, etc.) seem to have largely migrated away from the transgressive category that slurs are in.
“Words that have always been too offensive for Stronglang, and why” could be interesting.
LikeLike
Several authors and commentators have noted that slurs are increasingly the most taboo words. But I wouldn’t say they’re the only “truly” taboo words, since taboos vary considerably from one culture to another; some of the more traditional taboo words – those based on sex, excreta, religion – are still firmly transgressive in certain populations (or generations). There aren’t any words that are out of bounds for this blog, but obviously we haven’t covered them all.
LikeLike