Swearing varies a lot from place to place, even within the same country, in the same language. But how do we know who swears what, where, in the big picture? We turn to data – damn big data. With great computing power comes great cartography.
Jack Grieve, lecturer in forensic linguistics at Aston University in Birmingham, UK, has created a detailed set of maps of the US showing strong regional patterns of swearing preferences. The maps are based on an 8.9-billion-word corpus of geo-coded tweets collected by Diansheng Guo in 2013–14 and funded by Digging into Data. Here’s fuck:

The red–blue scale shows relative frequency. The frequency of a word in the tweets from a given county is divided by the total number of words from that county (which correlates strongly with population density). The result is then smoothed using spatial autocorrelation analysis, with Getis-Ord z-scores mapped to identify clusters. Alaska and Hawaii are not included.
Polysemy – a word’s multiple meanings – has not been controlled in the graphs, so the hell map includes straight religious uses as well as sweary ones, the pussy map includes cat references, and so on. But the graphs are nonetheless highly suggestive of differential swearword (and minced oath) clustering in different parts of the country.
Hell, damn and bitch are especially popular in the south and southeast. Douche is relatively common in northern states. Bastard is beloved in Maine and New Hampshire, and those states – together with a band across southern Arizona, New Mexico, and Texas – are the areas of particular motherfucker favour. Crap is more popular inland, fuck along the coasts. Fuckboy – a rising star* – is also mainly a coastal thing, so far.
Here’s the full glorious set in alphabetical order (click to enlarge):

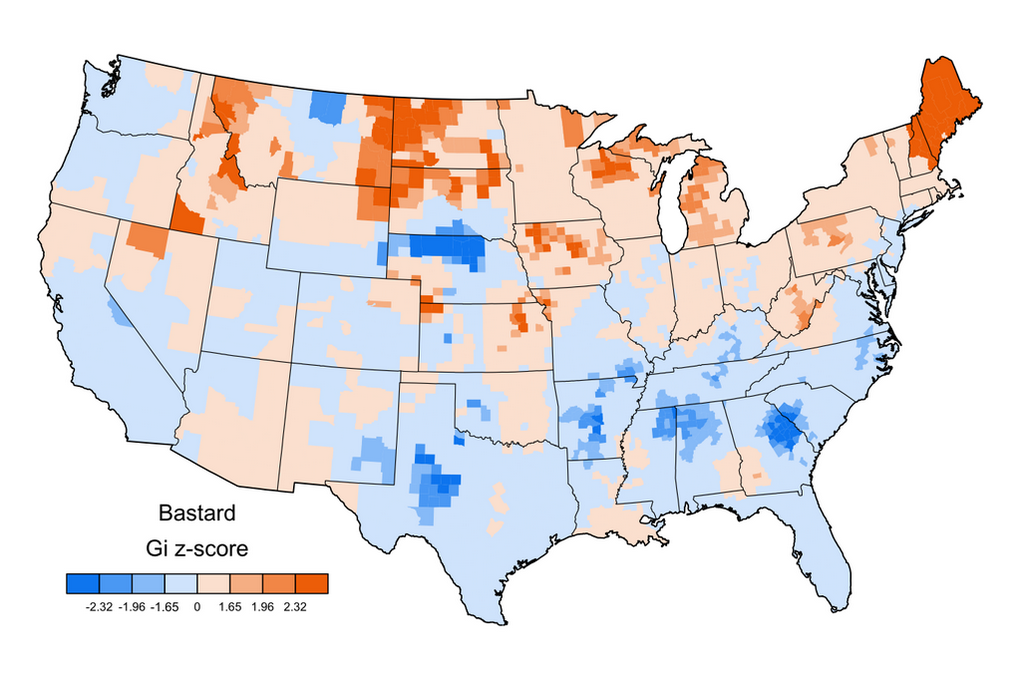






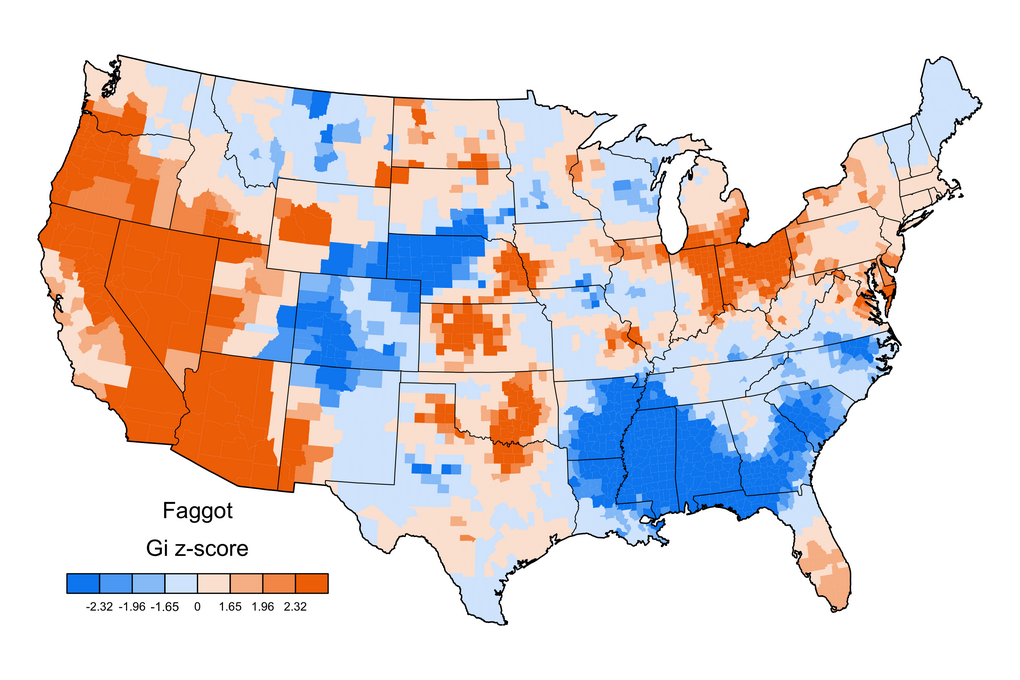









As Grieve put it, ‘pretty much everyone’s swearing. We just don’t all prefer the same words’. You can see more word-maps on his research blog and various publications elsewhere on his website. He and colleagues have been measuring the 100,000 most common words in American English (as manifested in the tweet corpus), so additional maps will be appearing, and he tells me Diansheng is also collecting UK data.
For more on the method of spatial analysis used to create the maps, see for example Grieve’s ‘A regional analysis of contraction rate in written Standard American English’ (PDF), or ‘A statistical method for the identification and aggregation of regional linguistic variation’ (PDF) (co-written with Dirk Speelman and Dirk Geeraerts), both from 2011.
https://twitter.com/StanCarey/status/626378685977899008
Updates:
See my follow-up post, Sweary maps 2: Swear harder, for ~60 more sweary heat maps and a link to Jack Grieve’s Word Mapper app, where you can run your own searches.
Some composite maps, including swears not covered above, are now available on Grieve’s blog. Here’s one with bollocks, bloody, piss, and crap:

Picked up by Washington Post, Kottke, Fusion, MetaFilter, Discovery, AJC, Mental Floss, WaPo again.
*
* Grieve’s presentation ‘Mapping lexical spread in American English’ (PDF) has data on the fastest growing words on Twitter in 2014, among other delights. Four of the top 10 are based on fuck. We’re becoming sweary asf.


This is some fucking bullshit.
LikeLike
It is, actually. They don’t even seem to now that “fuckboy” is the male equivalent of “whore.” They have the definition all wrong.
LikeLike
The word has multiple, evolving senses. We have a new post all about fuckboy.
LikeLike
I fucking love this site! I thought I knew how to swear until I joined the Marine Corps! I learned a whole new level and heard fantastic swearing from all over the country!
LikeLiked by 1 person
You really arę mad!
LikeLike
I read this : http://www.usnews.com/news/articles/2015-12-17/study-people-who-swear-more-are-smarter-have-larger-vocabulary and it made me feel so much better about my inability to refrain from swearing–now this site underscores that!
LikeLike
Your inability to stop swearing is bad. This site gives you a false sense of relief, first know you have a problem and then act to change your language.
LikeLike
Fuck that for a game of soldiers. Shuck off the chains of habit if you see them as chains but the disdain of the squeamish and pious is no reason to constrain your florid language.
The Oxford English Dictionary has over 600,000 words and only one of them is bad.
LikeLike
Language is always changing. Words that are in common vernacular today may have been yesterday’s vulgarities. Today’s vulgarities may be in common use and considered non-vulgar years from now, just add new terms will rise and be considered vulgar.
LikeLike
Anybody besides me bothered by the inclusion of hate language (faggot, slut, etc) with “swears”? I don’t just mean made uncomfortable – but also questioning the methodology.
LikeLike
We use ‘swear’ on this blog as a convenient catch-all term for taboo vocabulary in its many forms: this includes slurs and epithets. It’s not clear how this relates to Grieve and colleagues’ research methodology.
LikeLike
Gotcha. Still wondering why these terms and not others – maybe some of the more “loaded” terms get blocked by Twitter as hate speech and so don’t show up in their sample. Maybe I’ll take a look at the original study.
LikeLike
I’m not unbothered.
LikeLike
Interestingly, many of the hate speech terms are used by members of the affected groups as reclaimed terms. It is intriguing to speculate which areas are showing these terms as hate s peech and which are showing them as reclaimed terms.
LikeLike
I notice a trend of low z-score for Colorado and specifically the Denver metropolitan area. Is there a way to substantiate that across the board with a single graphic that there are indeed some places that just don’t “swear” much online?
LikeLike
where’s Dang?
LikeLike
You must have skipped the bit where I wrote:
See my follow-up post, Sweary maps 2: Swear harder, for ~60 more sweary heat maps.
Dang is among them.
LikeLike
A small note: I think you mean spatial autocorrelation in your third paragraph instead of spatial autocorrection. Spatial autocorrelation means that the z value (e.g. elevation, Getis-Ord) for any one point (or pixel/cell) is similar to those cells near to it because they are close to each other, and the process driving that z value is not independent at that scale.
LikeLike
Thanks for pointing this out. It’s fixed now.
LikeLike
Long Island, New York is most certainly the usage epicentre of the word, ‘f*uck!
LikeLike
I’m only offended by these ones:Fuck,bitch,motherfucker,shit,damn,ass,asshole and that’s about it,that is it i use all the time
LikeLike
Yes,I agree
LikeLike
Cunt,Douche,Whore,Darń,Bastard and Hell arę not swears
LikeLike
Why do these maps never include Alaska (or Hawaii?)
LikeLike
Gosh and darn? They stopped being vulgar in about 1908. “Bastard” sounds great in a Maine accent. Interesting additions would “hidden swear” words and phrases. Most famous would be “bless your heart” which is used throughout the south to mean “fuck you”. The rejection of Catholicism in much of Quebec led to the use of “tabernacle” as “fuck” in that region of Canada.
LikeLike
The point is that gosh and darn, regardless of their mildness, are still used as swears – and to different degrees in different places. We looked at swearing in Canada in another post.
LikeLike
Bless your heart, Janos Wimpffen. I married into southern culture. I do not claim to have it figured out, but it is safe to say that the use of BYH in the south is far more nuanced than can be reduced to a mere middle finger.
LikeLike
Just read that Quebec piece–excellent. Having spent a fair bit of time there I would agree. This leads to an interesting set of conjectures as to how many types of impacts there are by the use of the word “fuck”. 1) There is the very pointed and rare, it must be made by someone who rarely uses it. 2) the deliberate and direct hurt, sort of a subset of #1, 3) the casual and meaningless probably the most common since it can be a noun, adjective, adverb, verb used continualy) 4) the casual but highly artful (think Samuel L. Jackson). 5) the casual non-contextual, kind of the Quebec version but common anywhere where people are fluent in English but not raised in an Anglo-Culture. Working a lot in Continental Europe you will hear English speakers use it without any real depth, There’s even a cafe in Berlin named “Fuck” only an Anglo would be jarred by it.
LikeLike
WhenI was a kid, my parents would say “shit,” but nothing else, and they would insist that was not “cursing.” They said it was “black guarding.” That is not to be confused with “blackguard” as one word and pronounced as “blaggard,” meaning a bad person. It was pronounced like the two words “black guard” and it simply mean a lower forms of impolite language.
I am also curious why the people who examined this didn’t look for “goddamn” or any variation of it. I’d like to see the contrast between the Northeast’s use of it and the Bible Belt’s rejection of it.
LikeLike
Goddamn is one of 60 or so additional maps in my follow-up post, Sweary maps 2: Swear harder.

LikeLike